Glide 缓存解析
前言
Glide 是 Android 开发中大名鼎鼎的图片加载框架,它通过三级缓存实现了对图片加载的优化,又通过内部的图片池实现了对移动端内存的优化
这篇文章的目的是深入解析 Glide 加载一张来自网络图片时的流程及各种控制优化,基于 Glide V4 分析
简单使用
Glide 加载图片非常简单,一行代码足矣
1 | Glide.with(fragment) |
那我们以改代码为例,深入了解其加载流程,以及这期间涉及到的缓存模型
先提一些概念性的东西
- Model:数据源,可能是 url,资源 id 等等
- Data:源数据,来自于 model
- Resource:我们所需资源的包装类,内部有对象池的缓存和重用,所持有的资源是我们真正想要的,比如说 bitmap
- ModelLoader: 将 Model 转化成 Data,ModelLoader 有两个方法,一个 handles 表示是否可以处理这个类型的 Model,如果可以的话就可以通过 buildLoadData 生成一个LoadData,而 LoadData 包含了要用来做缓存的 key,及用来获取数据的 DataFetcher
- Decoder: Data 转化成 Resource
- ResourceTranscoder:对原始的 Resource 处理转化,比如说圆角啊,缩略啊
- Encoder:持久化数据,将原始的 Resource 持久化缓存到磁盘里,还有一个子类 ResourceEncoder,这个则是用来持久化处理过的 Resource 的
后面提到的工具都会在 Registry 里注册,这里展示一个最简单的数据第一次获取流程
流程解析
请求构建解析
Glide.with 方法
1 | public static RequestManager with(Fragment fragment) { |
返回了一个 RequestManager 对象,以供后续的代码调用,而 RequestManager 经过 getRetriever 方法层层追踪可以得知是由 Glide 单例对象中持有的 RequestManagerRetriever 中 RequestManagerFactory 工厂生成的,至于具体是如何生成的先略去不谈
RequestManager.load 方法
1 | public RequestBuilder<Drawable> load(@Nullable Object model) { |
通过传入的 model 构建一个加载 Drawable 的 RequestBuilder,还是处于请求构建阶段,那么最关键的加载过程应该追踪到 RequestBuilder.into 方法中了
RequestBuilder.into 方法
1 | public Target<TranscodeType> into(ImageView view) { |
这里做了一些校验判断,以及对 ImageView 的特殊处理(根据 transcodeClass 创建对应的 ImageViewTarget,这里应该是 Drawable.class),最终调用了真正的 into 方法
执行加载流程
1 | private <Y extends Target<TranscodeType>> Y into( |
追踪到 RequestManager.track 中发现最终会调用 Request.begin 方法,由于我们使用的是最简单的调用方式,所以 buildRequest 只是调用最简单的 SingleRequest.obtain 方法(这里采用了 Message 类似的对象池来防止频繁创建对象,因为在设置了缩略图和错误配置时会递归产生 requet 对象),直接追踪到 SingleRequest.begin 方法
SingleRequest.begin 方法
1 |
|
因为图片的加载是必须在宽高都明确了以后才执行,所以我们追踪到 SingleRequest.onSizeReady 方法
SingleRequest.onSizeReady 方法
1 |
|
图片的加载流程有 engine 负责,返回的 loadStatus 则是对这次引擎加载工作的描述,可以通过这个对象去取消此次加载。由于引擎的加载是基于异步的 io 操作,所以将 this 作为回调接口传入了。由于 Glide 的配置项非常多,所以其请求的构建流程也特别复杂,接下去就是真正的引擎加载流程
引擎加载解析
先来聊聊 engine 的主要构成
1 | // 引擎任务大小 |
具体这些是如何工作的,那就要结合加载过程来讲了
Engine.load 方法
1 | public <R> LoadStatus load( |
从这个流程中我们来详细解析一下 Glide 的缓存策略
缓存键 Cache Keys
1 | EngineKey key = keyFactory.buildKey(model, signature, width, height, transformations, |
缓存键通过该方法生成,包含至少两个元素
- 请求加载的 model(File, Url, Uri)
- 一个可选的签名(Signature)
另外(活动资源,内存缓存,资源磁盘缓存)的缓存键还包含一些其他数据,包括:
- 宽度和高度
- 可选的变换(Transformation)
- 额外添加的任何选项(Options)
- 请求的数据类型(Bitmap, GIF, 或其他)
活动资源和内存缓存使用的键还和磁盘资源缓存略有不同,内存缓存通常有适应内存选项(Options),比如影响 Bitmap 配置的选项或其他解码时才会用到的参数
为了生成磁盘缓存上的缓存键名称,以上的每个元素会被哈希化以创建一个单独的字符串键名,并在随后作为磁盘缓存上的文件名使用。后面会根据具体的使用场景说明
内存缓存
Engine.loadFromCache 方法
1 | private EngineResource<?> loadFromCache(Key key, boolean isMemoryCacheable) { |
Engine.getEngineResourceFromCache 方法
1 | private EngineResource<?> getEngineResourceFromCache(Key key) { |
cache 对象就是 MemoryCache 内存缓存实例,默认的实现是一个 LruCache – 最近最少使用算法,当缓存空间满了的时候,将最近最少使用的数据从缓存空间中删除以增加可用的缓存空间来缓存新内容。
MemoryCache 中有关于资源移除的监听回调,有 engine 实现相关接口,最终回调的是 ResourceRecycler.recycle(resource),最终调用的都是 Resource 自己实现的 recycle 方法释放对象已方便重用,拿最常用的 BitmapResource 来说吧,他就有一个 bitmapPool 用来存放已经释放的 bitmap 资源,新建的时候可以尝试着去 bitmapPool 去取(这里涉及到 inBitmap 相关知识,自行查阅),可以大大缓解内存抖动
活动资源缓存
Engine.loadFromActiveResources 方法
1 | private EngineResource<?> loadFromActiveResources(Key key, boolean isMemoryCacheable) { |
活动资源的引用比较简单,是一个参数为弱引用的池子,不用像内存缓存一样考虑缓存大小
磁盘缓存
根据 key 获取加载任务,如果已存在只需要把加载回调加入其中即可,因为相同的 key 代表着相同尅性的加载。如果不存在,再通过工厂新生成一个 EngineJob 和 DecodeJob,将 EngineJob 存入引用池后开始任务
这里要注意的是 glide 会对处理过的图片也进行缓存,默认状态是会先读取处理过的缓存数据,再读取原始缓存数据,最后才会尝试在数据源加载
EngineJob.start(DecodeJob) 方法
1 | public void start(DecodeJob<R> decodeJob) { |
这里会根据 DecodeJob 中持有的 DiskCacheStrategy 硬盘缓存策略来决定是否从硬盘缓存中读取还是从数据源读取(选取执行的线程池),无论选取哪个线程池,最终执行的都是 DecodeJob 的 run 方法
DecodeJob.run
1 |
|
run 方法交由 runWrapped 执行
DecodeJob.runWrapped 方法
1 | private void runWrapped() { |
默认的模式是从 INITIALIZE 状态开始的,那么就会
DecodeJob.runGenerators 方法
1 | private void runGenerators() { |
其实这个过程可以概括为
- 取当前状态 stage
- 获取当前 stage 下的 DataFetcherGenerator
- 执行 DataFetcherGenerator.startNext,如果返回 true 即找到了缓存数据,结束循环,等待 onDataFetcherReady 回调,否则取下一个状态 stage 循环上述过程
- Stage.FINISHED 状态且未找到缓存,加载失败
stage 主要包括处理过的缓存,原始数据缓存以及数据源
DataFetcherGenerator.startNext 内的主要逻辑就是生成一个缓存键,通过这个键去查找磁盘中可以缓存的 File,如果存在则再去查找对应的 ModelLoader,最后通过 ModelLoader 中持有的 DataFetcher 去加载数据,以 SourceGenerator 为例,因为它里面还包括了缓存的相关流程
SourceGenerator.startNext 方法
1 |
|
fetcher 加载完成会回调通知 onDataReady 方法
SourceGenerator.onDataReady 方法
1 |
|
DecodeJob.reschedule 方法
1 |
|
回到 DecodeJob.runWrapper 方法,由于 runReason = RunReason.SWITCH_TO_SOURCE_SERVICE 所以直接执行了 runGenerators 方法,其实第一次执行 SourceGenerator.startNext 时就已经先执行了这个流程,作为数据源请求,需要在别的线程池上跑
1 | if (dataToCache != null) { |
首先这个过程会被执行
SourceGenerator.cacheData 方法
1 | private void cacheData(Object dataToCache) { |
在 startNext 中,继续执行
1 | if (sourceCacheGenerator != null && sourceCacheGenerator.startNext()) { |
待到 sourceCacheGenerator 中对应的 fetcher 执行完毕就会回调 SourceCacheGenerator.onDataReady 方法,再回调 SourceGenerator.onDataFetcherReady 方法,最终回调
DecodeJob.onDataFetcherReady 方法
DecodeJob.onDataFetcherReady 方法
1 |
|
DecodeJob.decodeFromRetrievedData 方法
1 | private void decodeFromRetrievedData() { |
DecodeJob.notifyEncodeAndRelease 方法
1 | private void notifyEncodeAndRelease(Resource<R> resource, DataSource dataSource) { |
至此,最简单的一个加载流程已经完成,可以用一张图来表示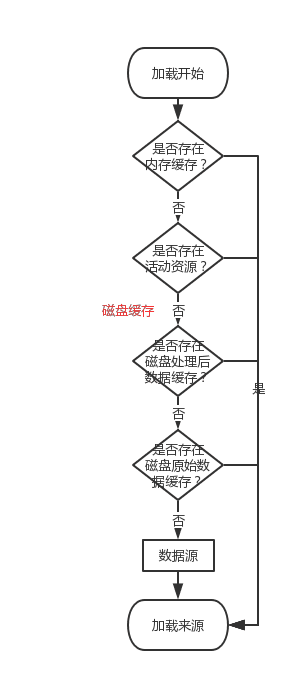
结语
本文从一个最简单的图片加载操作完整追踪整个缓存路径,虽然还有许多细节没有涉及到,但确实也是因为 glide 是个非常庞大的图片加载库,为了内存优化、性能改善做了非常多的努力,比如说对列表图片加载的优化等等,希望可以开个好头,激起你探索的兴趣吧