内存优化 —— ArrayMap,SparseArray
前言
HashMap 是 Java 中常用的 map 容器,凭借着可靠的链表数组结构,在增删改查方面的性能十分优异,但是 HashMap 确有着致命的缺点——内存占用很大,因为 HashMap 中数组占用的内存是提前申请好的,在某些条件下,hash 分布并不是平均的,甚至都是同一个位置,数组其他位置内存虽然被分配了,但是并没有被使用。而且数据不断增多还会触发数组的扩容,还会加剧这种状况(这是由 hashmap 的扩容算法决定的)
所以 Android 为解决这种状态,提供了内存效率更高的 ArrayMap 和 SparseArray,值得注意的是 ArrayMap 直到 API 19 才加入到 Android 中但是在 Support 包中有提供
本文基于 Android API 27,为了直观表现截取了部分 Android 性能优化典范视频的一些截图
ArrayMap
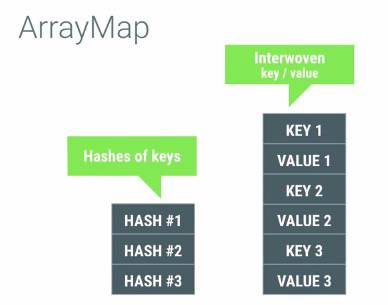
以 android.support.v4.util.ArrayMap 为例,下面是类注释中摘抄的一段关于 ArrayMap 原理的描述
It keeps its mappings in an array data structure – an integer array of hash codes for each item, and an Object array of the key/value pairs. This allows it to avoid having to create an extra object for every entry put in to the map, and it also tries to control the growth of the size of these arrays more aggressively (since growing them only requires copying the entries in the array, not rebuilding a hash map).
ArrayMap 通过两个数组实现映射关系,一个 int 数组用来存放 hash 值,而另外一个 object 数组存放 key/value 的组合。这种方式即可以避免为放入 map 的 kv 生成一个额外的对象(HashMap.Node,维护 hash 碰撞时的链表结构),也可以避免 hashmap 扩容时需要重建 map 的开销(只需要数组的复制)。忽略 Java Container API 的需求,真正的逻辑实现在 SimpleArrayMap 类中。
基本结构
ArrayMap 有两个主要组成结构,一个是存放 hash 值的 int 型数组 mHashs,还有一个就是 key value 依次对应存放的 object 型数组 mArray。数组中的元素紧密排列,可以极大的利用内存。
get 方法
ArrayMap.get 方法
1 |
|
get 方法先从 mHashs 数组中查找到对应的 index,然后映射得到 mArray 中的 index * 2 + 1 中的 value 值,继续追踪 indexOfKey 方法
ArrayMap.indexOfKey 方法
1 | public int indexOfKey(Object key) { |
根据策略选取 hashCode 的计算方法,System.identityHashCode 方法是通过对象的内存地址得到的 hashCode,继续追踪 indexOf 方法
ArrayMap.indexOf 方法
1 | int indexOf(Object key, int hash) { |
查找的逻辑比较简单,mHashs 数组是个有序数组,所以查找时可以使用二分查找(时间复杂度 O(log2n)),查找到 hash 的index 后可以去 mArray 中找到 key 比较来确定是否是我们要查找的 key,因为是两倍关系,可以通过位操作来提高性能。
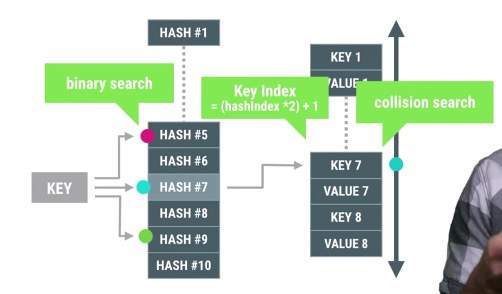
既然 mHash 是有序的,那么插入删除操作必须有排序的过程
put 方法
ArrayMap.put
1 | public V put(K key, V value) { |
虽然逻辑简单,但是设计地十分严谨,为了保证数据小容量下的频繁插入操作,有选择性的做了缓存数组。为了尽量少的拷贝数组,对 index 插入位置也做了优化,选取了数组靠后的位置。 remove 方法也类似,只是在数据大小大于 8,小于三分之一数组大小时会缩减数据,移除数据时也会做数据拷贝。ArrayMap 不支持并发操作
遍历
鉴于数组的结构,对于 ArrayMap 的遍历是十分高效的,我们可以直接使用数组下标访问对应内容
1 | for(int i = 0; i < map.size(); i++){ |
值得一提的是,空的 ArrayMap 并不会占用内存。虽然 ArrayMap 对于节省内存方面做了许多优化,但是这种数据拷贝的方式在大数据场景下其实是非常浪费性能的。所以 ArrayMap 适用于数据量千以下的使用场景
SparseArray
HaspMap 的另一个缺点就是存放的 key/value 都必须是对象,对于以基本数据类型(boolean, int, long等)需要存入的是其包装类(Boolean, Integer, Long等),对于 HaspMap 的增删改查很容易产生大量自动拆装箱操作,这是很影响性能的。因此 Android 提供了一下容器来替代这种基本数据类型下的 map 操作。
| class | \<key, value> |
|---|---|
| SparseArray | \<int, obj> |
| SparseBooleanArray | \<int, boolean> |
| SparseLongArray | \<int, long> |
| LongSparseArray | \<long, obj> |
下面以 SparseArray 为例,对其中的优化进行追踪说明
基本结构
与 ArrayMap 相似,有个两个数组,一个是存放 key 的 int 型数组,另一个是存放 value 的 object 数组,相对于 ArrayMap 来说简化了不少,因为 key 本身就可以看做是 hash 了。
get 方法
SparseArray.get 方法
get 方法调用了 get(key, valueIfKeyNotFound) 方法
1 | public E get(int key, E valueIfKeyNotFound) { |
和 ArrayMap 一样,key 数组也是有序的,通过二分查找寻找目标 key,只是这里少了 hash 产生碰撞时的逻辑。而且这里有一个 mValues[i] == DELETED 的判断,说明删除时的逻辑和 ArrayMap 不同,是以一个 DELETED 去替代,省去了数据拷贝相关操作。先查看 remove 操作再追踪 put 方法查看扩容相关逻辑。
remove & put
remove 其实调用的是 delete
1 | public void delete(int key) { |
delete 在只是在将要移除的 value 指向一个 DELETED 引用,并将 mGarbage 标志位置为 true,意味着数组中有被移除的数据
1 | public void put(int key, E value) { |
SparseArray.gc 方法
1 | private void gc() { |
逻辑比较简单,就是如果对应位置已经被删除了,那么就把后面的数据往前拷贝,最后剩下的置为 null,操作后保证前 o 个数据是有效的,剔除了被移除数据
可以看出 SparseArray 的删除操作是非常有效率的,但是缺少了减小数组的相当操作
结语
Android 为